

DR.GEEK
Oct 31, 20201 min read
How supervised learning typically works
(31th-Oct-2020) Choosing a model-class: – A model-class, f, is a way of using some numerical parameters W, to map each input vector, x,...
(31th-Oct-2020) Choosing a model-class: – A model-class, f, is a way of using some numerical parameters W, to map each input vector, x,...

(30th-Oct-2020) • Supervised learning: Regression

(29th-Oct-2020) It is very hard to write programs that solve problems like recognizing a three-dimensional object from a novel viewpoint...

(28th-October-2020) • DNN has achieved great results - a large margin in performance ratio of existing methods - still room for...

(27th-October-2020) There is a thread on reddit about “best framework for deep neural nets”. DL4J also gives DL4J vs. Torch vs. Theano...

(26th-October-2020) • Deep Learning is now of the hottest trends in Artificial Intelligence and Machine Learning, with daily reports of...

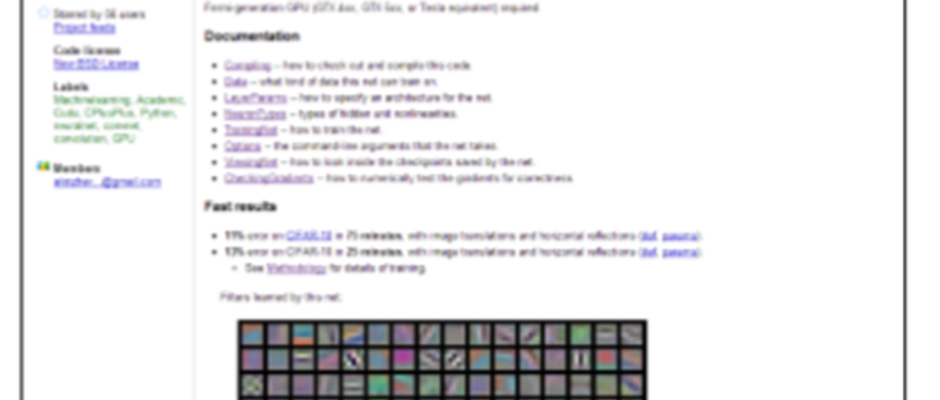
(24th-October-2020) Code of the Supervision team of ILSVRC 2012 champion • nVidia GTX 580 GPUs • Linux and CUDA • Data file creation • -...

(23rd-October-2020) • Convolutional NN model applied to generated model • Probabilistic max-pooling is proposed to incorporate max-pooling.

(22nd-October-2020) 1. • Learn two- and three-tier DBM models with MNIST (Handwritten Numerical Data Set) • Generate 𝑝𝑝 (𝐯𝐯) samples...

(21th-October-2020) 1. Adjustment to maximize the likelihood of the entire DBN 2. Copy it to another deterministic structure (Neural Net...

20th-October-2020 Marginal distribution 𝑝𝑝 (𝐡𝐡 3 | 𝐯𝐯) can not be calculated analytically We introduce approximate distribution ,...

19th-October-2020 Persistent CD: Improved Contrastive Divergence • Use 1 for next parameter update. DEEP BELIEF NETWORK

18th-October-2020 What if I quit 𝑇𝑇 at finite times? It corresponds to the minimization of the objective function called Contrastive...

17th-October-2020 At the limit of 𝑇𝑇 → ∞, 𝐯𝐯𝑇𝑇 is distributed 𝑝𝑝 (𝐯𝐯; θ Θ). Generate distribution 𝑝𝑝𝑇𝑇 (𝐯𝐯) close to -...

16th-October-2020 • From the nature of RBM 𝑝𝑝𝐡𝐡𝐯𝐯; θθ, 𝑝𝑝 (𝐯𝐯 | 𝐡𝐡; θθ) can be computed analytically Learning RBM (Gibbs...

15th-October-2020 • The learning of a general Boltzmann machine is impractical because it takes exponential time of n, but in the RBM...

14th-October-2020 • A restricted Boltzmann machine (RBM) is a generative stochastic artificial neural network that can learn a...

13th-October-2020 • KL distance: an index for measuring proximity between probability distributions • minimization of KL distance:...

12th-October-2020 Modeling the probability distribution using an energy function • Structure in which simultaneous random variables are...